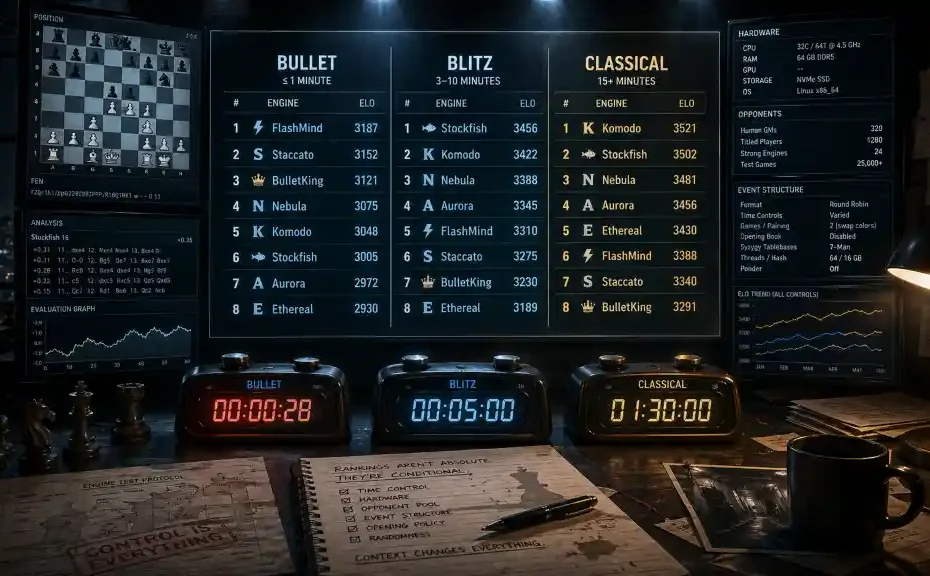
Time Control Changes Engine Rankings
Chess engine rankings are often read as if they were universal measures of strength. A table places one engine above another, assigns an Elo value, and gives the impression of a stable hierarchy. In reality, engine rankings are always connected to the conditions under which the games were played. One of the most important of those conditions is time control.
A ranking produced from bullet games does not measure exactly the same environment as a ranking produced from blitz games. A classical ranking, in turn, should not be collapsed into the same meaning as a fast-time-control list. Engines may share the same executable name, evaluation architecture, and search code across formats, but their practical performance can still change when available thinking time changes.
For IJCCRL readers of chess engines ratings lists, this distinction is essential. A rating list should not be interpreted only by looking at Elo numbers. It should be interpreted by asking what was measured, under what time control, against which opponents, with what hardware, and under what event structure. Time control does not merely change the speed of the game. It changes the testing environment itself.
The purpose of this article is to explain why time control engine rankings can differ across bullet, blitz, and classical formats, and why responsible comparison requires methodological caution.
1. Time control is part of the measurement
A chess engine rating is not an abstract value detached from testing conditions. It is an estimate of relative performance in a defined environment. If that environment changes, the meaning of the rating changes.
CCRL makes this explicit by separating rating surfaces according to time control. Its 40/15 rating list states the testing context, the time control, the hardware equivalence, tablebase conditions, number of games, and the rating method used. The CCRL 40/15 page reports that the list is based on more than 2.29 million games and identifies the time control as equivalent to 40 moves in 15 minutes on an Intel i7-4770k, computed with Bayeselo. (Computer Chess)
That disclosure matters because the Elo value is only meaningful inside the conditions that generated it. A reader cannot safely take a number from one time-control environment and compare it directly with a number from another unless the methodology and pool are understood.
This is the first rule of responsible interpretation: time control is not a label attached after the ranking is created. It is one of the variables that defines the ranking.
2. Bullet rankings measure a high-pressure environment
Bullet engine games give each engine very little time to search. In such environments, performance may depend heavily on speed, efficient move ordering, pruning behaviour, time management, tactical immediacy, and the ability to avoid catastrophic mistakes under severe time pressure.
This does not mean bullet rankings are inferior. They are simply measuring a different competitive condition. A bullet list can be useful, especially when the goal is to examine fast decision-making, short-time tactical stability, or practical performance in rapid engine tournaments.
However, bullet rankings should not be treated as a complete substitute for longer-time-control rankings. A strong bullet performer may not always retain the same relative edge in classical conditions. Conversely, an engine that scales well with more time may appear less dominant in bullet.
For IJCCRL, this is why the Derived Stockfish Bullet surface should remain clearly separated from Classical and Blitz surfaces. A bullet rating list can be accurate within its own framework, but it should not be presented as a universal engine hierarchy.
The safest language is not “Engine A is stronger than Engine B” in absolute terms. The more precise statement is: “Engine A performed better than Engine B in this bullet environment, under these rules, against this opponent pool.”
3. Blitz rankings sit between speed and depth
Blitz is often interpreted as a compromise between bullet and classical. That is partly true, but it should not lead to careless conclusions. Blitz still places significant pressure on time management, search efficiency, and engine stability. At the same time, it gives engines more opportunity to resolve tactical complexity than bullet.
This middle position makes blitz useful for tournament ecosystems. It can produce a large number of games faster than classical while still allowing more meaningful search than bullet. But blitz does not automatically predict classical order.
Some engines may be very efficient at short depths and therefore perform well in bullet or blitz. Others may require more time before their evaluation and search characteristics become fully visible. The ranking can therefore shift when moving from bullet to blitz, and again when moving from blitz to classical.
This is why IJCCRL should treat ratings lists by time control as separate technical surfaces. The separation is not cosmetic. It protects the meaning of each list.
4. Classical rankings measure a longer search environment
Classical engine games allow deeper search, more stable long-term planning, and more extensive exploitation of engine evaluation strengths. They may also reduce certain forms of fast-time-control volatility.
In TCEC’s league rules, time control increases as the season progresses: lower leagues use 30 minutes plus increment, Premier Division uses 60 minutes plus increment, and the Superfinal uses 120 minutes plus increment. This shows that a major engine tournament can deliberately attach different competitive significance to different stages and time controls. (Chessdom Wiki)
That structure is important for interpretation. A longer time control is not merely a slower version of a fast game. It may produce a different competitive signal. Search depth, evaluation reliability, endgame conversion, long manoeuvring, and resilience against opening pressure can all become more important.
For IJCCRL, the Classical Original UCI Track is therefore not just another list beside the Bullet Derived list. It is a separate measurement environment, using a different hardware pool, different time control, different engine family structure, and different publication meaning.
5. Engine scaling is not uniform
A central reason rankings change by time control is that engines do not always scale identically with extra time.
One engine may gain more from deeper search than another. A second engine may be exceptionally fast at finding strong practical moves under short limits. A third may have better time management. A fourth may be more vulnerable to low-time errors or to positions requiring long strategic accumulation.
These differences are especially relevant in modern computer chess, where many engines are close in strength. When the margins are small, a change in time control can be enough to reorder part of the table.
This does not mean that rankings are random. It means that the ranking is conditional. The same engine can be legitimately ranked differently in bullet, blitz, and classical lists because each list is answering a different question.
A bullet list asks: how did these engines perform under very short thinking time?
A blitz list asks: how did they perform under moderate short-time tournament conditions?
A classical list asks: how did they perform when given longer search horizons?
Those are related questions, but they are not identical questions.
6. Opponent pool also interacts with time control
Time control does not operate alone. It interacts with the opponent pool.
A rating list built from one set of engines can differ from a list built from another set. This is particularly important when comparing Original UCI engines with Stockfish-derived engines. A pool made mostly of original engines does not have the same competitive structure as a pool dominated by close Stockfish-family derivatives.
If the opponent pool changes and the time control changes at the same time, direct comparison becomes even more dangerous. A Bullet Derived Stockfish ranking and a Classical Original UCI ranking are separated by more than one variable. They differ by time control, engine family, hardware pool, and competitive environment.
For that reason, IJCCRL should avoid presenting one combined interpretation across those two surfaces. The responsible approach is to keep each ranking inside its methodological lane.
The reader can compare narratives across lists, but not collapse the Elo values into one universal order.
7. Hardware and time control cannot be ignored
Hardware matters in engine testing. Processor architecture, available threads, memory, tablebase access, and system stability can all influence performance. Time control then interacts with those hardware conditions.
A short time control on one hardware pool is not equivalent to the same nominal time control on a significantly different pool. Even when the nominal clock is identical, the number of nodes searched, depth reached, and practical search quality may differ.
This is why IJCCRL’s separation between the AVX2 Original UCI pool and the SSE4.1/POPCNT Derived Stockfish pool should remain explicit. That separation protects the integrity of the rating surfaces.
A ranking is stronger when it tells the reader where it came from. It becomes weaker when hardware, time control, and pool identity are hidden or merged.
8. Tournament structure changes the meaning of results
Time control also interacts with tournament format. A round robin, a knockout match, a league division, and a superfinal do not produce the same type of evidence.
TCEC’s league system, for example, defines multiple events, including leagues, Premier Division, playoff structures, and a Superfinal. It also specifies that events run continuously until all scheduled games are played, and that engine updates are not allowed during events. (Chessdom Wiki)
Those rules show why tournament context matters. A rating list can include many games across a broad pool, while a knockout match may decide a winner from a narrower head-to-head contest. Both are valuable, but they should not be confused.
In IJCCRL terms, an event winner and a rating leader are related but different concepts. A knockout winner has won a defined match or event. A rating leader has the highest estimated performance in a specific rating dataset. Time control influences both, but the interpretation remains different.
9. Faster lists can be useful without being final authority
It would be a mistake to dismiss bullet or blitz rankings. Faster lists are useful for several reasons.
They allow more games to be played in less time. They help reveal short-time tactical stability. They can make live tournaments more dynamic. They can provide early signals before longer-time-control lists mature.
But usefulness is not the same as final authority. A bullet list may be a valid bullet list without being a valid classical list. A blitz ranking may be strong evidence for blitz performance without proving the same order at 40m+2.
This is the methodological balance IJCCRL should preserve. Fast-time-control ratings can be published, followed, and discussed, but they must remain labelled by time control and separated from other formats.
10. Longer lists also have limits
Classical rankings are often treated as more serious because the engines have more time to think. That is reasonable in many contexts, but classical lists also have limits.
They take longer to build. They may contain fewer games over the same calendar period. They may be more expensive in hardware time. They may respond more slowly to engine updates. A classical list can therefore be more stable but less immediately responsive.
The correct conclusion is not that one time control is always superior. The correct conclusion is that each time control answers a different question.
Bullet emphasizes speed and short-time robustness.
Blitz balances volume and search.
Classical emphasizes deeper search and longer-game stability.
A serious rating ecosystem should make those distinctions clear rather than forcing all formats into one artificial hierarchy.
11. How readers should compare time-control lists
Readers should use a cautious method when comparing rankings across time controls.
First, identify the time control. Do not compare a bullet Elo directly with a classical Elo unless the list publisher explicitly explains how the scales relate.
Second, check the engine pool. A list of original UCI engines and a list of Stockfish-derived engines are not measuring the same population.
Third, check the hardware. If the hardware pool differs, the interpretation must be even more cautious.
Fourth, look at game count. A list with more games usually has a stronger evidence base, although game count alone does not solve every methodological issue.
Fifth, distinguish provisional standings from final rating publication. An active tournament table is not the same as a closed, audited rating surface.
Finally, avoid exaggerating small differences. If two engines are close in Elo, especially in a provisional or low-game-count environment, the responsible conclusion may be that they are approximately comparable under those conditions.
12. What IJCCRL should preserve editorially
IJCCRL’s strongest editorial position is to keep its rating surfaces clean, track-aware, and time-control-aware.
The home page can reinforce the broad semantic cluster around chess engine rating lists. The Events page can define what is currently running and what will run next. The current tournament calendar can explain the annual structure. The Downloads page can preserve publication-valid material. The Archive can preserve closed events. Winners can record event champions. Rating pages should remain focused on ratings, not become general event reports.
This separation matters because it prevents confusion. A reader should know whether they are looking at:
a live event,
a provisional standing,
a rating list,
a closed event,
a downloadable pack,
or a historical winner record.
Time control must be visible across that structure. Bullet, blitz, and classical should not be treated as interchangeable labels.
Conclusion
Time control changes engine rankings because it changes the competitive environment. Bullet, blitz, and classical games do not test engines under identical conditions. They differ in search depth, time-management pressure, tactical volatility, hardware interaction, tournament structure, and rating maturity.
A responsible reader should not collapse all rankings into one universal claim. A responsible publisher should not invite that mistake. The safer and more accurate approach is to treat each rating list as a controlled estimate of performance under defined conditions.
For IJCCRL, that means preserving separate rating surfaces by time control, keeping Original UCI and Derived Stockfish tracks apart, and linking each ranking to the event, rules, downloads, and archive context where relevant.
A time-control-specific ranking is not weaker because it is specific. It is stronger when its limits are clearly stated.
Sources / References
CCRL 40/15 Rating List — All Engines.
Used for public examples of time-control disclosure, game volume, hardware equivalence, tablebase conditions, and Bayeselo-based rating publication. (Computer Chess)
TCEC Leagues Season Rules.
Used for examples of staged tournament structure, increasing time controls, event rules, engine update restrictions, and live rating publication notes. (Chessdom Wiki)
TCEC official website.
Used as the official public live surface associated with the Top Chess Engine Championship ecosystem. (tcec-chess.com)

Jorge Ruiz Centelles
Filólogo y amante de la antropología social africana