How to Compare Chess Engines Fairly
Comparing chess engines sounds simple until the details are examined closely. One engine scores better in a match, another has a higher Elo in a public list, and a third performs strongly in a different tournament format. At first glance, these facts may appear to describe the same thing. In practice, they often do not. A fair comparison requires much more than putting two engines side by side and reading a final score.
For readers who follow chess engines ratings lists, the central issue is methodological discipline. A rating, a match result, or a tournament standing is only meaningful when the surrounding test conditions are clearly defined and controlled. Without that discipline, comparisons become noisy, and rating claims can easily be overstated.
This matters because chess engine performance is not a fixed, context-free property. It is an observed result under a particular testing framework. Hardware, time control, opening policy, adjudication rules, tablebase settings, colour balance, software version, and sample size can all change the outcome. Therefore, the fair question is not simply “Which engine is stronger?” but “Which engine performed better under these exact conditions, and how confident should we be in that conclusion?”
What “fair” comparison actually means
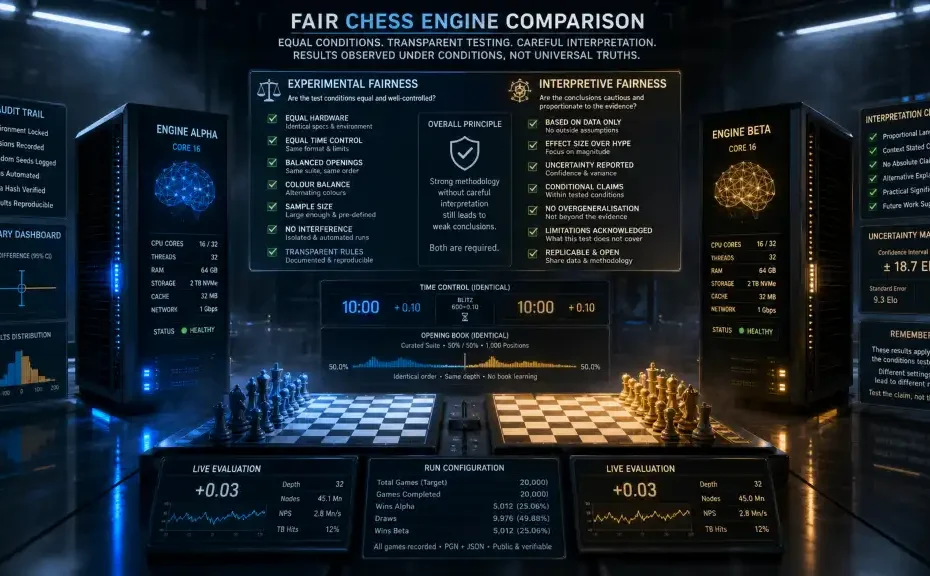
A fair engine comparison means that the engines are tested under conditions that are as equal and transparent as possible, and that the resulting claims do not go beyond what the data can support. This principle is consistent with how serious public engine testing is approached. Large rating lists such as CCRL emphasise clearly defined testing frameworks, while formal competition rules such as those discussed in the Chessdom rules material show how heavily tournament fairness depends on stable conditions. Chessprogramming’s material on playing strength also helps remind readers that playing strength is observed through results, not measured as a universal, context-free constant.
In other words, fairness has two parts:
- Experimental fairness: equal and well-controlled conditions for the engines.
- Interpretive fairness: cautious, proportionate claims about what the results mean.
Both parts are necessary. Even a well-run test can be misinterpreted, and even careful language cannot rescue a poorly designed test.
Why this matters for engine ratings readers
Readers often encounter ratings or match summaries without the full methodological background. An engine may be described as “stronger” because it leads a table or wins a recent match, but this can hide important distinctions. Was the rating computed from thousands of games or only a small sample? Were the openings neutral and balanced? Did both engines play the same number of games with White and Black? Were the binaries compiled consistently? Did tablebase rules or adjudication policies favour one type of position?
These questions are not secondary details. They are part of the result itself. A rating list is not just a table of numbers; it is a product of a testing environment. That is why readers who consult an engine ratings hub should always be prepared to read beyond the headline Elo figure.
A rigorous checklist for comparing chess engines fairly
1. Define the comparison question precisely
Before looking at scores, define what is actually being compared. Is the goal to compare two engines at blitz, classical, or bullet time controls? Is the goal to compare tournament performance, head-to-head match strength, or rating-list performance inside a larger pool? Is the target practical strength under a specific opening suite, or general performance across a wide range of positions?
If the question is vague, the interpretation will also be vague. “Engine A is stronger than Engine B” is not precise enough. “Engine A scored better than Engine B in a 100-game match at 5+2, with fixed balanced openings and equal hardware” is a much stronger and more honest statement.
2. Use identical hardware and runtime conditions
A fair comparison requires the same hardware environment for both engines. CPU model, thread count, hash size, operating system behaviour, and access to tablebases can materially affect results. A faster machine does not simply make the test more efficient; it may change the relative performance of the engines themselves.
This is particularly important because some engines scale differently with hardware. An engine that performs very well on one thread may not scale in the same way at higher thread counts. Another may benefit more from larger hash or faster memory. Therefore, when comparing engines, the hardware configuration is not background noise. It is part of the method and must be reported clearly.
3. Keep the time control fixed and relevant
Time control is one of the strongest determinants of observed engine performance. An engine that performs well at bullet may not rank the same way at classical. Search behaviour, pruning decisions, time management, and evaluation stability can produce different relative outcomes depending on the available thinking time.
For this reason, it is unsafe to move directly from one time-control context to another. A fair comparison does not treat blitz Elo as a universal statement about all forms of play. It treats it as evidence about performance under blitz conditions.
When reading or publishing results, always ask:
- What was the exact time control?
- Was increment used?
- Were all games played under the same clock rules?
- Is the comparison being made only within that time-control context?
4. Control the openings carefully
Opening policy is one of the most important safeguards against distorted results. If engines start from arbitrary or unbalanced positions, or if one side benefits disproportionately from the opening set, the final score may say as much about opening selection as about engine strength.
Serious testing commonly uses balanced opening suites and mirrored colour assignments. In practice, this means that if one engine receives White in a given opening, the engines later swap colours from the same or equivalent starting position. This helps reduce opening bias and colour bias.
Without that control, one engine may gain an artificial advantage from repeatedly entering positions that fit its style or preparation better. A fair comparison must therefore describe the opening source, the opening depth or ply limit if applicable, and the balancing method.
5. Ensure exact colour balance
Colour balance is a basic requirement. Each engine should receive the same number of games as White and as Black. If a comparison ends with unequal colour distribution, the final score becomes harder to interpret.
This point may seem obvious, but it is worth stating because many casual comparisons overlook it. At scale, even a small imbalance can matter, especially under short time controls or opening books with measurable White-side influence.
6. Record adjudication and tablebase rules
A result is only comparable when the termination logic is clear. Were games played to mate, stalemate, repetition, or standard draw rules only? Was adjudication used for clearly won or drawn positions? Were Syzygy or other tablebases enabled, and if so, to what depth or piece count? Was the 50-move rule respected in the configured tablebase environment?
These are not technical footnotes. They affect how games end and therefore can affect scores. Two test runs with different adjudication thresholds or different tablebase policies are not methodologically identical, even if everything else looks similar.
Readers who want trustworthy results should pay close attention to the surrounding rules and audit framework, because that is where many hidden differences become visible.
7. Use a meaningful sample size
One of the most common mistakes in engine comparison is drawing strong conclusions from too few games. A short match can be interesting, but it is not always decisive. Random variation, opening-specific effects, and ordinary statistical noise can easily distort a small sample.
This is one reason large public lists remain useful. Their value does not come from Elo figures alone, but from the volume and structure of the underlying testing. More games do not guarantee perfect truth, but they usually provide a more stable estimate than a handful of games.
Therefore, a fair comparison should always state the number of games and resist making absolute claims from limited evidence. If the sample is small, the conclusion should be correspondingly modest.
8. Distinguish observed rating from “true strength”
This is the conceptual checkpoint that many readers miss. A published rating is an estimate derived from results, not a direct measurement of a hidden essence. The engine’s “true strength” is not fully known. It is inferred from performance in a given testing environment.
That distinction matters because readers often over-interpret rating gaps. A lead of a few Elo points may be suggestive, but it is not a metaphysical proof that one engine is universally superior in all contexts. The estimate depends on who was played, under what conditions, with how many games, and under which rating model.
Fair comparison therefore requires intellectual restraint. Ratings are useful, but only when read as estimates with context, not as timeless and universal facts.
9. Report the rating model and uncertainty
Different rating systems are designed to estimate playing strength from game outcomes, but they are still models. Bayeselo and Ordo, for example, both aim to convert results into rating estimates, yet the interpretation of those estimates depends on the broader test design and the data supplied to the model.
When publishing or comparing ratings, it is good practice to state:
- which rating method was used,
- what game pool was included,
- whether the list is closed or open,
- and whether confidence intervals or uncertainty indicators are available.
A rating with no methodological explanation is much harder to interpret fairly than a rating accompanied by transparent context.
10. Compare like with like
A fair comparison should avoid mixing incompatible categories without warning. A result from one rating pool should not automatically be treated as directly equivalent to a result from another. Likewise, performance from original UCI engines and Stockfish-derived engines may be discussed in the same editorial ecosystem, but readers should be careful when moving between distinct pools, datasets, or event structures.
This does not mean cross-category discussion is impossible. It means the boundaries must be explicit. Pool identity, participant set, and event design all affect meaning.
11. Verify the engine build and configuration
Version identity matters. Two binaries with similar names may not be methodologically comparable if they were compiled differently, configured differently, or launched with different options. The same engine can behave differently depending on thread settings, learning files, contempt-related settings if applicable, or specific author-recommended options.
Fairness therefore includes software identity control. A serious comparison should record the exact engine names, versions, and relevant runtime options rather than relying on broad labels alone.
12. Audit the game file, not just the scoreboard
The final score is not the whole dataset. PGN integrity matters. Invalid moves, broken terminations, duplicated games, and other technical anomalies can distort a result if they are not detected. A fair comparison must therefore include some degree of audit discipline, especially when the result is intended to support a public claim.
For readers, this means that a published score should ideally be connected to an inspectable game record, not just a headline. Transparency increases confidence. Opaque results reduce it.
Common unfair comparison habits
Several habits repeatedly produce weak or misleading conclusions:
- treating one short match as conclusive proof of general superiority;
- comparing ratings from different pools as though they were directly interchangeable;
- ignoring hardware differences;
- ignoring time control differences;
- using unbalanced or poorly documented openings;
- publishing final scores without game-level audit transparency;
- describing rating estimates as if they were absolute, universal truth.
None of these habits is unusual, but all of them weaken fairness.
Methodological limits that readers should keep in mind
Even a carefully designed comparison has limits. No practical test covers every possible opponent, every possible opening structure, and every possible runtime environment. Engine testing always involves trade-offs between realism, control, cost, and scale. Therefore, fairness does not mean perfection. It means reducing avoidable bias, documenting the conditions, and staying honest about uncertainty.
This is also why a fair article or rating note should avoid exaggerated claims. It is reasonable to say that one engine outperformed another under a given framework. It is less reasonable to declare universal superiority without specifying the framework. The stronger the claim, the stronger the methodological burden should be.
Conclusion
To compare chess engines fairly, readers need more than a score or an Elo number. They need a checklist: equal hardware, fixed time control, balanced openings, exact colour balance, transparent adjudication and tablebase rules, meaningful sample size, clear rating methodology, verified engine identity, and audited game records. Above all, they need to remember that a rating is an estimate produced under conditions, not a timeless measurement detached from context.
That does not make engine comparisons less useful. It makes them more serious. A careful comparison is not just a stronger technical exercise; it is also a more honest one. For anyone reading engine ratings, match reports, or tournament summaries, that is the proper standard.
References

Jorge Ruiz Centelles
Filólogo y amante de la antropología social africana